PostgreSQL: find sequences of same-parameter values within ordered groups
Recently I’ve been solving a problem of finding database items that have to be grouped by one parameter (let’s say a name), then ordered by the timestamp within each group. The tricky part was to find groups where the last N most recent items all have the same second parameter (say, a flag). A colleague of mine pointed out to even more interesting variation of the same problem: find such groups that contain sequences of the size N of rows with the same flag.
Let’s create a table to illustrate the problem for the sequence size of 3 or more and a flag A:
CREATE TABLE names (
name varchar(5),
dt timestamp,
flag varchar(1)
);
INSERT INTO names
(name, dt, flag)
VALUES
('Name1', '2020-01-01 00:00:00', 'A'),
('Name1', '2020-02-01 00:00:00', 'A'),
('Name1', '2020-03-01 00:00:00', 'A'),
('Name1', '2020-04-01 00:00:00', 'B'),
('Name1', '2020-05-01 00:00:00', 'B'),
('Name1', '2020-06-01 00:00:00', 'A'),
('Name1', '2020-07-01 00:00:00', 'B'),
('Name1', '2020-08-01 00:00:00', 'A'),
('Name2', '2020-01-01 00:00:00', 'A'),
('Name2', '2020-02-01 00:00:00', 'A'),
('Name2', '2020-03-01 00:00:00', 'B'),
('Name2', '2020-04-01 00:00:00', 'A');
What we would like to have:
- The result should be grouped by the name column
- Within the group, the rows should be ordered by dt column
- We are interested only in the groups containing sequences of 3 or more rows with the flag A
As we see in the data above Name1 has a sequence of three rows with the flag A (with dt 2020-01-01, 2020-02-01, and 2020-03-01). All other ordered by date consecutive rows with the same flag have two items or less. Thus the resulting SQL query should return Name1.
Whenever we need to group a set by the subsets of rows (windows) and then do something over these subsets, window function comes in handy. In this case, we would use ROW_NUMBER() that assigns a sequential integer to each row in a result set.
Postgres window functions have PARTITION BY clause that divides rows into multiple partitions. We can use more than one column here to group by the name and the flag columns. Let’s explore it:
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY name ORDER BY dt ) AS name_part,
ROW_NUMBER() OVER (PARTITION BY name, flag ORDER BY dt) AS name_flag_part,
ROW_NUMBER() OVER (PARTITION BY name ORDER BY dt ) - ROW_NUMBER() OVER (PARTITION BY name, flag ORDER BY dt) AS seq
FROM names
ORDER BY name, dt
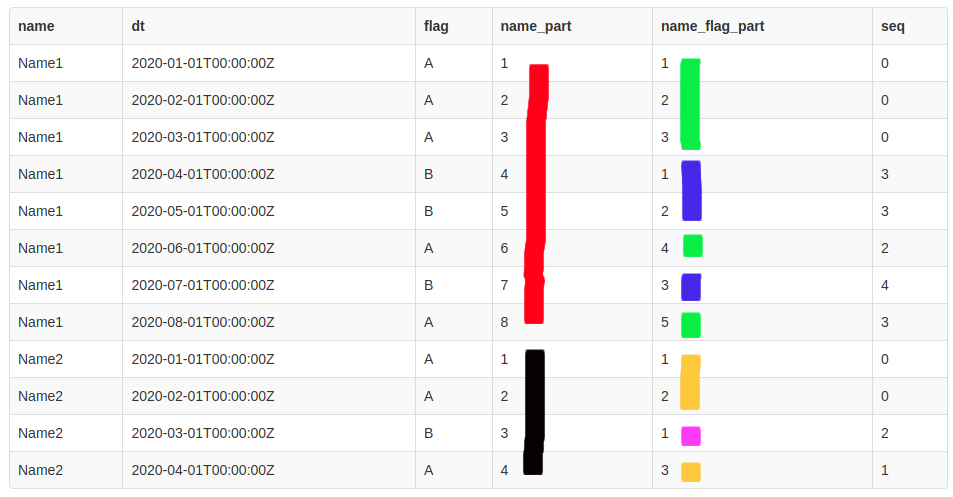
As you can see partitioning by the name column in ROW_NUMBER() function assigns consecutive row numbers within groups by the name column (a red bar for the Name1, a black one for Name2).
When partitioning by the two columns name and flag we have independent numbering within each name group for each flag subgroup:
- green (flag A, name Name1)
- blue (flag B, name Name1)
- yellow (flag A, name Name2)
- magenta (flag B, name Name2)
Given these numberings, how can we detect a sequence occurrence? We can subtract a row number for name and flag partitioning from the row number for the name column partitioning (see alias seq above). The subtaction gives each flag subgroup the same numbers that we can use for counting:
SELECT
name,
MIN(dt) AS min_dt,
flag,
COUNT(name) AS counter,
seq
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY name ORDER BY dt ) - ROW_NUMBER() OVER (PARTITION BY name, flag ORDER BY dt) AS seq
FROM names
) numbered
GROUP BY name, flag, seq
HAVING COUNT(name) >= 3 AND flag = 'A'
ORDER BY name, min_dt

We do the following:
- Find the difference between row numbers when partitioning by a name and partitioning by a name and a flag
- Group the set by name, flag and the difference from the step above
- Apply filtering for the grouped result to find sequences with flag A only with 3 or more rows
- Order by the name and the timestamp of the first row in the sequence
Now that we found the solution let’s finalize the query to meet our goal:
SELECT
DISTINCT name
FROM (
SELECT
name,
flag,
COUNT(name) AS counter,
seq
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY name ORDER BY dt ) - ROW_NUMBER() OVER (PARTITION BY name, flag ORDER BY dt) AS seq
FROM names
) numbered
GROUP BY name, flag, seq
HAVING COUNT(name) >= 3 AND flag = 'A'
) filtered
ORDER BY name
Summing up the post I would say that SQL and PostgreSQL specifically is a powerfull tool worth learning. Window functions allow doing some sophisticated analytics with a single SQL query.