Python interview questions and answers
Although the questions you find in this blog post are universal, they are crafted for a technical interview for a web developer position.
The questions have been tested in real life: I used them in more than 35 interview sessions. They allowed my team and me to hire three brilliant developers: a junior developer (ex-Yandex), a middle developer (ex-Yandex), and a senior one.
The questions have also been reviewed by my peers and got positive feedback. Some of my colleagues use these questions in their technical interviews. I also use the questions when consulting people about preparing for the interview or getting their first software job.
The questions are not unique. I’m not revealing any professional secrets by posting them. The single most valuable thing about these questions is the principle they are combined in an interview session. You can also use these questions to come up with your questions for the Python interview as an interviewer. Also, you can use them to prepare for an interview as an interviewee.
Table of Contents
- Introduction
- Python questions
- How language evolves
- Basic types and data structures in Python
- Function default arguments
- What’s decorator?
- Decorator that prints function execution time
- Using decorator
- Decorated function’s name
- Decorators for generators
- Decorator with arguments
- Class variables
- List slices
- What’s list/dict comprehension?
- Generator expressions
- What useful functions from functools do you know?
- Asyncio, multithreading, multiprocessing
- Python ecosystem
- Computer science questions
- Databases
- Testing
- DevOps/SysAdmin skills
- System Design and Architecture
- Sources and useful links
Introduction
Premises
- Software development is no longer an art, nor a lifelong quest, but rather an everyday office job, though highly-skilled one. That’s why a candidate’s abilities for teamwork, coping with chores are super important. But pure computer science, algorithms are in the background, whether you like it or not.
- An algorithm-based technical interview is an analogue of IQ-tests that have been invented in the early XX century in the US for a quick military recruits categorization. IQ provides some insights about human intelligence but also has its flaws. Demonstrated algorithm skill also provides an insight about candidate’s intelligence but also has its flaws. Algorithm-based technical interviews are used by corporations to quickly process a huge queue of candidates, hire the ones they need and evaluate their grades and salary. Corporations everybody wants to work for can afford a false negative in hiring, i.e. not hiring the right person, as many candidates compete to be hired by these companies. If you are not one of these companies, then you compete with other companies for the candidates. So don’t pretend to be a Google if you are not Google.
- Human intelligence neither is an “on/off”, nor a range. Rather, intelligence is a swiss army knife, a multitool. It may contain an excellent sharp blade for everyday chores, it may also have a screwdriver that merely works, and it may also have a corkscrew that you actually don’t need at all. Can we evaluate an overall score for such a multitool? Sure. But why would we? Unless you are Google, find a multitool with the blades and bits that solve your exact problems, not the abstract ones.
- You need an interview to find out three things: a) why the candidate has left (or are ready to leave) his/her previous (current) job; b) what is he/she looking for at the new company; c) what value can he/she bring to your team?
- Hiring error can be mitigated by the probationary period. Take it seriously. Set some goals (tasks) for probation. The same for the candidate: during probation decide if the company is the right choice. But hiring error is still an error that costs your company money and time. You should do your best to avoid this error. The same for the candidate. That’s why you never tell lies about your project and team in the interview. Still, there’s nothing wrong with presenting your project positively. Actually, it’s your duty if you want to hire someone in a highly competitive job market.
- There are no two identical interviews even for the same grade. The technical interview is always improvisation. It’s an attempt to reveal a candidate’s boundaries of competence, strengths and weaknesses in a short period of time.
Candidates & CVs
- Not everybody is a CV-ninja. Really
- Too high salary expectations isn’t a reason to reject a candidate CV. You always can ask questions that will either lower the expectations or prove you are interviewing a genius.
- (sarcasm mode on) Of course, an interviewer always knows best! (sarcasm mode off) But there are no solid grounds for reject candidate CVs with grammar mistakes or expressions of inexperience or quirks in their CVs. Asking inadequately complex questions is also not a good idea. The interview is not about you, it’s about the candidate.
- Don’t afraid of people with some irrelevant background, e.g. designers, analysts, etc., who changed his/her profession to a technical one. Be honest, your boring REST API doesn’t require a university graduate program.
- A candidate’s technology stack may not be 100% yours. Still, he/she may be a good match for your team. Should you hire someone with 3+ years of experience with Flask but no Django experience for your Django project? Probably you should.
- The only way to hire someone quickly is to do as many interviews as you can.
- Average interview time for an interviewer is about 2.5 hours (skim over the CVs, prepare for the interview, the interview itself, discussion with an HR specialist and a CTO)
- Don’t make a technical interview for too long. 2 hour is enough. 1.5 hours is optimal.
- Three interviews a week is a good pace. More than 3 is too much for the interviewer and his/her team. Less than 3 makes your search longer.
- Average time for hiring a Python developer depends on the project, expected experience and your offer conditions. As a rule of thumb, 3 months from submitting an open position to HR department to the first working day is okay.
- Not every software engineer is an introvert. There are people with outstanding “selling” skills who are prepared for typical interview questions, present themselves, but still lack solid knowledge of software development. Don’t let them trick you! Ask whiteboard programming questions!
Non-technical questions
- What have you done in your previous/current project?
- Describe your team line-up (frontend/backend developers, QA engineers, SRE/DevOps/SysAdmins, product/project managers, etc)?
- How planning, code review, etc. are organized in your project? What you liked and disliked about it?
- Why did you decice to leave (have already left) the project?
- What do you expect from the new project (things to develop, processes, etc)?
Python questions
How language evolves
- What’s new in the latest Python version? (Python 3.8 at the moment of writing)
- How Python 3+ differs from Python 2.7? (What’s new in Python 3)
- What new syntax has been introduced since Python 2.7? (minimal expectations: asyncio, type hinting)
Basic types and data structures in Python
- What are the basic types in Python?
- What are the basic data structures in Python?
- All data types and structures in Python can be divided into two groups. Name these groups (mutable, immutable)
Problem. What lines of the following code raise exceptions? What expectations?
d = {}
d['a'] = 1
d[(1,2)] = 2
d[[1,2]] = 3 # TypeError: unhashable type: 'list'
d[(1,2,[3,4])] = 4 # TypeError: unhashable type: 'list'
Function default arguments
Problem. We have got a function:
def fun_default(val, lst: list=[]) -> list:
lst.append(val)
return lst
What the following print statements will print after the block of assignments is executed?
l1 = fun_default(1)
l2 = fun_default(2, [])
l3 = fun_default(3)
print(l1) # [1, 3]
print(l2) # [2]
print(l3) # [1, 3]
How would you fix the function so that print statements print [1], [2], [3] respectively?
def fun_default_fixed(val, lst: list=None) -> list:
if lst is None:
lst = []
lst.append(val)
return lst
What’s decorator?
- What’s decorator?
- What decorators from the standard library you know?
- Tell about descriptor protocol (complex question)
Decorator that prints function execution time
We have got a function that queries a database. We want each function call to print time of its execution. Implement it with a decorator. Assume: decorated function may have any number of positional or keyword arguments.
import time
def measure(func):
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
Using decorator
How do you apply your decorator to a function fun using syntactic sugar and without it?
# with syntactic sugar
@measure
def fun(l: list) -> None:
pass
# sugar free
fun = measure(fun)
type(fun) # function
Decorated function’s name
What is function docstring and name after decorator is applied?
fun.__name__ # 'wrapper'
fun.__doc__ # 'Wrapper function'
How do you return the original name and docstring to the decorated function?
from functools import wraps
import time
def measure(func):
@wraps(func)
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
@measure
def fun(l: list) -> None:
"""My func"""
pass
fun.__name__ # 'fun'
fun.__doc__ # 'My func'
How would you do that without functools.wraps?
import time
def measure(func):
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
wrapper.__doc__ = func.__doc__
wrapper.__name__ = func.__name__
return wrapper
Decorators for generators
What time do we get if we decorate a generator function like the following?
from typing import Generator, Any
def fun_gen(l: list) -> Generator[Any, None, None]:
for i in l:
yield i
Why time we see is so small? How would you measure the real time of iteration over the whole generator?
import time
from typing import Generator, Any
def measure_gen(func):
def wrapper(*args, **kwargs):
before = time.time()
result = yield from func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
@measure_gen
def fun_gen(l: list) -> Generator[Any, None, None]:
for i in l:
yield i
Decorator with arguments
Rewrite the decorator from the previous question so that it could take in an argument for a limit. Execution time is printed if it exceeds the limit.
def measure(limit):
# Don't forget to set limit when decorating a function!
def outer_wrapper(func):
def inner_wrapper(*args, **kwargs):
before = time.time()
result = func(*args, **kwargs)
after = time.time()
elapsed = after - before
if elapsed > limit:
print(f"Time elapsed: {after - before} seconds")
return result
return inner_wrapper
return outer_wrapper
How do we decorate a function using syntactic sugar and without it?
new_measure = measure(3)
fun = new_measure(fun)
fun([1,2,3])
# sugar free
new_measure = measure(3)
fun = new_measure(fun)
fun([1,2,3])
Class variables
What’s a class variable?
Problem.
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
What will the following print statements print?
print(Parent.x, Child1.x, Child2.x)
# 1 1 1
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
# 1 2 1
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
# 3 2 3
List slices
Problem. What are the results of this code block execution?
l = [1, 2, 3, 4, 5]
l[1:2] # [2]
l[:-1] # [1, 2, 3, 4]
l[10:] # []
l[10] # IndexError
What’s list/dict comprehension?
Implement a list of even numbers in a range [0, 10) to the power 2 using list comprehension.
[i*i for i in range(10) if i % 2 == 0]
Implement the same using map and filter.
map(lambda x: x * x, filter(lambda x: x % 2 == 0, range(10)))
Generator expressions
What’s the easiest way to turn the above list comprehension into a generator (generator expression)?
(i*i for i in range(10) if i % 2 == 0)
What useful functions from functools do you know?
The question may be a follow-up for decorator questions and functools.wraps. functools is a great module with loads of useful things. What would be great to hear from the candidate is something like reduce and partial.
Asyncio, multithreading, multiprocessing
- What’s the difference between a process and a thread?
- Problem. We have got a list of 1000 URLs, we have to iterate over it and make GET requests. How would you do that? (IO-bound tasks -> asyncio, Tornado etc или multithreading)
- Problem. We have got 1000 video files than should be rendered somehow using Python. How would you do that? (CPU-bound tasks -> multiprocessing)
- Give an overview of asyncio or similar libraries for asynchronous programming. How does it work? (huge question, expectations are covered in Trio tutorial)
Python ecosystem
- What do you use for background tasks in a Python project? (celery)
- How do you pack your Python code? (wheels, eggs, what’s the difference?)
- How do you document your Python project? (sphinx-doc)
- What do you use for REST API documenting? (swagger)
- What ORM do you use? (SQLAlchemy, Django ORM)
- What static analysis tools and linters for Python code do you use? (mypy, flake8)
- What web frameworks do you use? (Flask, Django, aiohttp, sanic, etc.)
- What package management tools do you use? (pip, pipenv, poetry, etc.)
Computer science questions
Time complexity
- What’s time complexity?
- What’s Big O?
- What’s time complexity for the following algorithm?
# O(n^2)
for x in n:
for y in n:
print(x, y)
What’s time complexity for each of these statements?
x in/not in s # where type(s) is list/tuple # O(n)
x in/not in s # where type(s) is set # O(1)
list.append() # O(1)
list.insert() # O(n)
list[index] # O(1)
list.sort # O(n log n)
Check out other data structures time complexity if needed.
Balanced brackets in a Lisp-program problem
Problem. I like to code in Racket, which is a Lisp dialect that uses a lot of brackets. Implement a Python function that takes in text and returns True if brackets in the text are balanced, and returns False otherwise.
{kind=link}
Examples of balanced brackets:
"()"
"(())"
"(custom-set-variables '(inhibit-startup-screen t) '(package-selected-packages (quote
(sql-indent magit dockerfile-mode yaml-mode gitlab markdown-mode lorem-ipsum jedi
elpy anaconda-mode afternoon-theme))))"
"(hello [world {!}])"
Examples of unbalanced brackets:
"("
")("
"())"
"({))"
def balance(s):
"""
Return True if string's parentheses are balanced, False otherwise
>>> balance("")
True
>>> balance("(())")
True
>>> balance("))((")
False
>>> balance("()()(())(()())")
True
>>> balance("(]")
False
"""
opening = {"(", "[", "{"}
closing = {")", "]", "}"}
mapping = dict(zip(opening, closing))
stack = []
for ch in s:
if ch in opening:
stack.append(mapping[ch])
elif ch in closing:
if (not stack) or (ch != stack.pop()):
return False
return not stack
If needed the function can be simplified to check only for round brackets.
Databases
Why RDBMS?
Problem. We are a startup with CTO, CEO and a couple of devs. We have no admins yet. We are developing authentication service (users registration, access rights, etc) in Python. Why do we need a database? Why not using a simple text file? Python has all we need to write to and read from a text file. We can just write user login and password hash to the file when the user is signing up. And then we read the credentials when the user is signing in in. It’s easy. It doesn’t require database admin work. Why not a text file?
If needed, the question can be put this way: what mechanisms of a relational database do you know, that are complex enough to implement, but are necessary for our case?
DB features that the candidate expected to mention:
- index
- relations
- transactions
The candidate may be asked to elaborate on each of these features. For example, you can ask him/her about indices:
- What’s time complexity for searching using the index?
- Problem. In table candidates we have a is_interviewed column with possible values 0 or 1. How adding an index for this column will affect search performance?
- What’s composite index (or multicolumn index)? What are the rules of using composite index?
MySQL/PostgreSQL queries
Problem. We have got service like iTunes where users can buy or rent a video. This is a PostgreSQL database schema for the service:
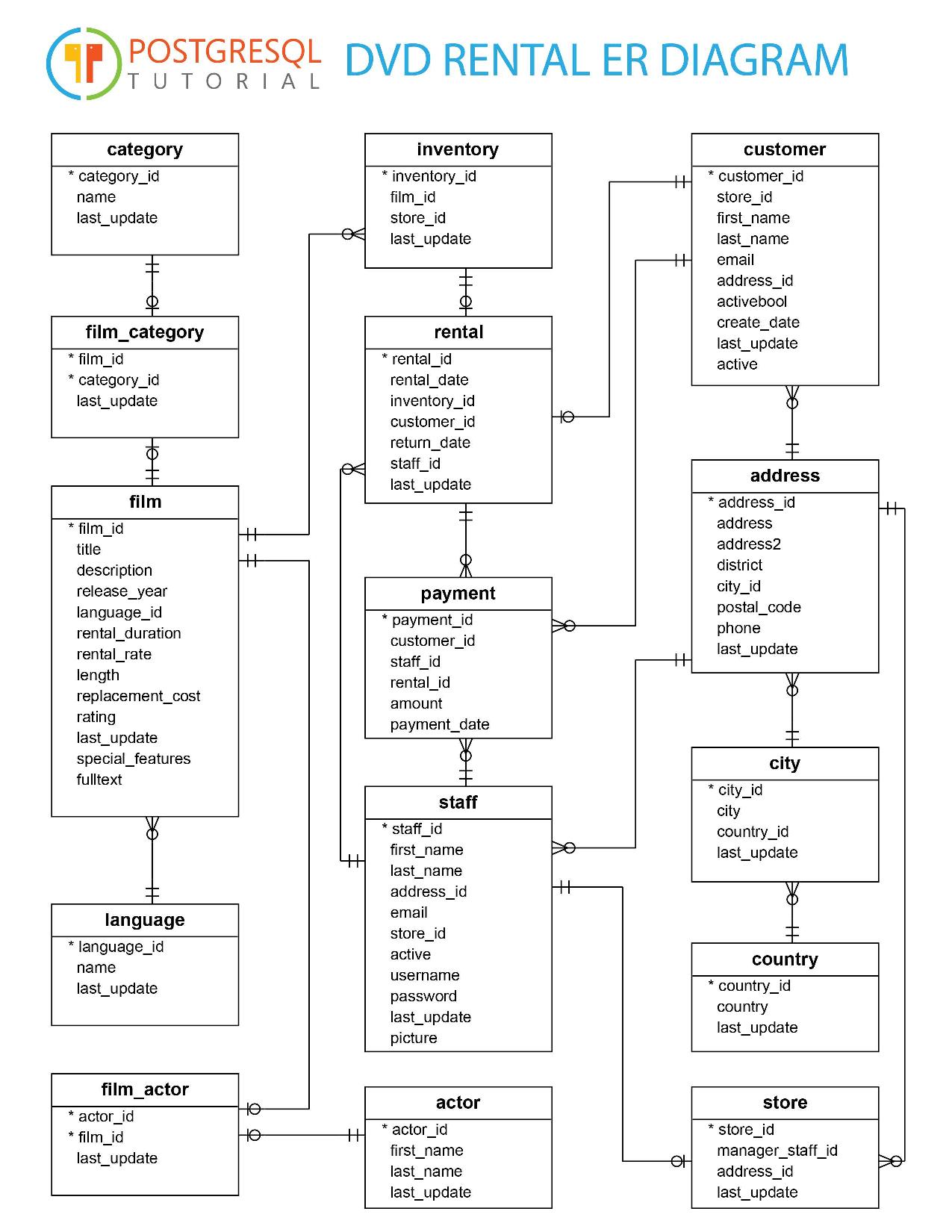
Write a SQL query to select top-20 movies starring actor John Doe. The query also selects:
- Movie title
- Movie language
- Movie release year
Results should be ordered in descendant order by a release year.
(If help needed) use tables: film, language, film_actor, actor
SELECT f.title, l.name, f.release_year
FROM film AS f
JOIN language AS l ON l.language_id = f.language_id
JOIN film_actor AS fa ON fa.film_id = f.film_id
JOIN actor AS a ON a.actor_id = fa.actor_id
WHERE a.first_name = 'John' AND a.last_name = 'Doe'
ORDER BY f.release_year DESC
LIMIT 20;
Write a SQL query to select top-10 customers who paid most, but not less than 100. The query also selects:
- Customer’s ID and full name
- Customer sum of payments
(If help needed) use tables: payment, customer
SELECT c.customer_id, c.first_name, c.last_name, SUM(p.amount) AS money
FROM payment AS p
JOIN customer AS c ON c.customer_id = p.customer_id
GROUP BY c.customer_id
HAVING SUM(p.amount) >= 100
ORDER BY money DESC
LIMIT 10;
NoSQL Overview
- What’s NoSQL?
- What types of NoSQL do you know?
- What NoSQL DB did you use?
Minimal expected answer: NoSQL is a database for collections of data. Data is denormalized, JOIN is not supported (usually implemented in your app).
Types of NoSQL DBs:
- key-value store (hash table implementation: Redis, AeroSpike)
- document-store (like key-value but with documents, e.g JSON, for values: MongoDB)
- wide column store (HBase, Cassandra)
- graph database (Neo4j)
Redis Overview
- What’s Redis is used for?
- Why it’s so popular for caching layer?
- How Redis is different from MySQL when it comes to data storage?
- What happens if a machine that runs Redis server is rebooted?
- What high availability mechanisms for Redis do you know?
Expectations: Redis is an in-memory key-value DB. Data snapshot mechanism can be used in Redis to dump data to the disk. Redis Sentinel is a mechanism for high availability.
Testing
Unit-testing overview
- What’s unit-testing?
- How it’s different from integration or functional testing?
- What libraries did you use for testing in Python? (unittest, pytest) How they are different from each other?
- When you write a unit-test? (in the existing project, in the new project, when fixing a bug, when implementing a new feature)
How do you test a function that changes data in MySQL?
Problem. We’ve got a function that executes a INSERT SQL query in the test database. Other developers in your team use the same database. We need to write a unittest for the function. But we don’t want to change test DB on each test run. How do you do it?
- mock
- transaction rollback
DevOps/SysAdmin skills
Broken response from google.com
Problem. When I open a browser, go to https://www.google.com and see the raw response, it’s normal text.
Here I do a GET request using curl, but a response seems to be broken.
> GET / HTTP/2
> Host: www.google.com
> User-Agent: curl/7.58.0
> Accept: */*
> Accept-Encoding: gzip, deflate
%�j��~d+.K�W��me`�,x�x�m�G�67��`$#������~{d���]�.'����
����Q���Mʥu���<�O),�&�����,���E�.���_�
&�I\��p��#]�,�����K+����p�vk
j���k"�fe�=�`�J4�I/��m6{�E���;3+�v�BT1T��(W��J��m�yO��
�j��
Why is it so?
curl -v "https://www.google.com" --header "Accept-Encoding: gzip, deflate" --output -
IP addresses top from Nginx log
Problem. Our service is under high load because of DDoS-attack. It makes hard for our legitimate customers to get a response from the service. We want to ban IP addresses bots get used of. To do so we want to make a top of IP addresses with the most requests. We ask our admins to provide web server logs as a file nginx.log.
Using console GNU utils create a file with top IP-addresses with most requests in descending order. Assume that IP-address is in 9th column in the log, columns are separated by t.
awk '{print $9}' nginx.log | sort | uniq -c | awk '{print $1","$2}' | sort -r -t, -nk1 > bots.csv
Docker
- What’s a docker container?
- What’s the difference between docker and virtualbox or other virtual machines?
- Why docker? We can just copy files to the real hardware machine
- Why not using virtualenv instead of Docker?
System Design and Architecture
Parental advisory: highly opinionated content (35+)
System design of pastebin-like service
User story (business description)
- A user submits text (copypasta)
- Text is saved, the user gets a unique URL (base serive URL + short path)
- User goes to the URL and sees his/her original text
- Text is stored until it’s expired
- Service deletes expired texts
- Once the text is expired, it’s not accessible anymore by its URL
- Service is operating under high load
- A product owner needs monthly statistics for URLs visits
Assume
- Copypasta can be in text format only
- The product owner doesn’t need realtime statistics
- Service gets 10 million new copypastas a month (3.85 RPS)
- Service has 100 million copypasta reads a month (38.5 RPS)
- We need capacity planning (hardware planning) for 3 years
Hints
- Average text size is 1Kb
- Short URL path takes 7 bytes in DB
- URL expiry (or TTL) takes 4 bytes in DB
- URL timestamp takes 5 bytes in DB
- File path to a copypasta takes 255 bytes in DB
- In total: 1.27 KB per copypasta or 1.27 Gb of copypasta a month
Capacity planning for 3 years
- 36 * 12.7 = 457 Gb of copypasta
- 36 * 10 = 360 million URLs
Service architecture
Client
|
V
Load Balancer
|
V
Web Server (Reverse Proxy, i.e. Nginx)
| |
V V
Write Read Analytics (MapReduce)
API API--------------------------- | |
| | | | | |
| V | | | |
| Cache | | | V
------------------------------ | | SQL for Analytics
V | | | |
SQL----------- | V V V
|_Master | | Object (File) Store
|_Slave V |
SQL V
^ Read-only Replica
|
|
Periodic Task
(remove expired)
Write API
- Generate a URL, check for unique constraint in SQL
- If the URL is unique, make an INSERT into DB table, otherwise go to 1.
shortlink char(7) NOT NULL
expiration_in_minutes int NOT NULL
created_at datetime NOT NULL
paste_path varchar(255) NOT NULL
PRIMARY KEY(shortlink)
CREATE INDEX shortlink_idx ON pastes (shortlink) USING BTREE;;
CREATE INDEX created_at_idx ON pastes (created_at) USING BTREE;;
Unique URL path generation
- Generate a random string md5(“user IP address string” + “timestamp string”)
- Encode string from 1 with Base 62 (like Base 64 but without escape characters)
def base_encode(num, base=62):
digits = []
while num > 0
remainder = modulo(num, base)
digits.push(remainder)
num = divide(num, base)
digits = digits.reverse
- Get first 7 characters from base62 string: it’s 62**7 possible short paths (which is much more than we need in our 3 years plan, i.e. 360 million URLs)
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
Request Write API
$ curl -X POST https://pastebin.com/api/v1.0/paste \
--data '{ "expiration_in_minutes": "60", "paste_contents": "My paste" }'
Write API Response
{
"shortlink": "xJlsmeT"
}
Request Read API
$ curl https://pastebin.com/api/v1.0/paste?shortlink=xJlsmeT
Read API Reponse
{
"paste": "My paste"
"created_at": "YYYY-MM-DD HH:MM:SS"
"expiration_in_minutes": "60"
}
Statistics
Since we don’t need realtime analytics, let’s use Nginx logs and process them in MapReduce
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Emit key value pairs of the form:
(2016-01, url0), 1
(2016-01, url0), 1
(2016-01, url1), 1
"""
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key.
(2016-01, url0), 2
(2016-01, url1), 1
"""
yield key, sum(values)
Sources and useful links
- Toptal Python Interview Questions
- Python Interview Questions (junior, middle, senior)
- System design interview
- The Python Language Reference
- PostgreSQL Tutorial