Вопросы и ответы для собеседования веб-разработчика на Python
tags: python interview ru
Ниже вы найдете принципы проведения и вопросы для технического собеседования на позицию Python-разработчика. Хотя вопросы довольно универсальны, больше всего они подойдут для области веб-разработки.
Вопросы прошли испытания боем: с их помощью было прособеседовано больше 35 кандидатов. Из них 3 (2 экс-Яндекс) стали частью моей команды в 2018 году, и еще 1 кандидат вышел в параллельную команду.
Вопросы получили положительный отклик коллег: люди используют их в каком-то объеме для собеседований в своих компаниях. Я также использую эти вопросы для консультации людей, которые готовятся к прохождению технического собеседования.
В то же время вопросы едва ли можно считать уникальными. Здесь нет никаких профессиональных тайн. На мой взгляд, основное преимущество вопросов — их система и принципы. На их основе можно составлять свои интересные и полезные вопросы для проведения собеседования, скроенные для ваших нужд. Или готовиться к техническому интервью в качестве кандидата.
Содержание
- Введение
- Python
- Проверка знаний, как развивается язык
- Основные типы и структуры данных в Python
- Порядок вычисления дефолтных аргументов функций
- Что такое декоратор?
- Декоратор, выводящий в stdout время выполнения функции
- Применение декоратора
- Имя декорированной функции
- Декоратор для генераторов
- Декоратор с аргументами
- Переменные класса
- Слайсы в списках
- Что такое list/dict comprehensions?
- Generator expressions
- Какие полезные функции из модуля functools ты знаешь?
- Asyncio, multithreading, multiprocessing
- Экосистема языка
- Алгоритмы
- Базы данных
- Тестирование
- DevOps/Администрирование
- Архитектура
- Полезные ссылки
- Errata
Введение
Предпосылки
- Разработка софта больше не искусство, не дело жизни, а обычная, хотя и высококвалифицированная офисная работа. Поэтому особенно ценно в кандидате то, как он работает в команде, как справляется с повседневной работой. Как бы банально и избито это ни звучало. А вот гениальные технические озарения и хитрые алгоритмы, на втором плане. Те, для кого на первом, сами знают, каким должно быть техническое собеседование.
- Алгоритмическое собеседование это аналог IQ-тестов, изобретенных американскими учеными в начале XX века для быстрой категоризации больших масс призывников по родам войск. IQ дает представление об интеллекте человека, но не исключает ошибок. Умение решать алгоритмические задачи тоже дает представление об интеллекте человека, но не лишено недостатков. Алгоритмические собеседования нужны крупным компаниям, которым требуется быстро отобрать нужных людей из огромных масс кандидатов и установить на входе грейд и зарплату. Они могут позволить себе ошибку ненайма, потому что кандидаты конкурируют за позиции в этих компаниях, а не наоборот, как большинстве других случаев. Не стройте из себя Google, если вы им не являетесь.
- Интеллект человека это не бинарное “есть/нет” и не диапазон. Интеллект — это что-то вроде швейцарского армейского ножа-мультитула. В нем может быть острое и практичное лезвие для повседневного использования, не слишком удобный штопор, которым все же можно пользоваться, и бесполезная отвертка, которой не сделаешь ничего. Можно ли дать интегральную оценку такому мультитулу? Наверное, можно. Но непонятно, зачем. Если вы не Google, конечно. Подбирайте нож под свои задачи и исходя из своих возможностей.
- Собеседование нужно, чтобы понять, почему человек ушел (или готов уйти) с текущего места работы, что он ищет на новом месте и что он может предложить команде.
- Ошибка найма обычно компенсируется испытательным сроком. Нужно отнестись к нему серьезно и выдать задание на этот период. Аналогично со стороны сотрудника. И все-таки ошибка найма — это ошибка, которая стоит вам времени и денег. Лучшее ее не совершать. Аналогично для сотрудника. Поэтому врать про проект не стоит. Но уметь его красиво преподнести нисколько не зазорно. Напротив, в условиях конкуренции компаний за кандидатов, это ваша прямая обязанность.
- Не бывает двух одинаковых собеседований даже для кандидатов одного уровня. Техническое собеседование это всегда импровизация, попытка найти границы компетентности и сильные стороны кандидата за короткий промежуток времени.
Отбор кандидатов
- Не все люди умеют составлять резюме.
- Слишком высокие зарплатные ожидания у интересного кандидата – не повод отказываться от собеседования. Всегда можно позадавать вопросы, которые снизят неоправданные зарплатные ожидания. Или подтвердят, что перед вами гений.
- Интевьюер, несомненно, самый умный и замечательный. Но это не повод забраковывать резюме с грамматическими ошибками (как учат вас горе HRы), смешными формулировками с проявлениями юношеской неопытности и всяким таким прочим. Задавать неоправданно сложные вопросы тоже не стоит. Оставьте высокомерие при себе.
- Не нужно бояться звать на собеседование человека, который раньше работал дизайнером/юристом/прорабом на заводе, но переучился на разработчика. Будем же честны, разрабатывать вашу скучную REST API много ума не надо, а профильное образование нужно далеко не везде.
- У кандидата может не быть 100% попадания в ваш технологический стэк, что не помешает ему в нем очень быстро разобраться. Скорее всего, неразумно отвергать кандидата с опытом работы с Flask 3 года, но без опыта работы с Django, на ваш заурядный Django-проект. Ну правда.
- Единственный способ быстро найти разработчика: провести как можно больше собеседований
- Среднее время, которое затратит интервьюер на 1 собеседование: ~2.5 часа (отсмотр резюме, подготовка к интервью, само интервью, общение с HR и CTO).
- Не стоит делать техническое интервью дольше 2 часов. Идеально 1.5 часа.
- 3 собеседования в неделю – это хороший темп. Больше – тяжело (физически для интервьюера, для HR в смыле поиска кандидата и для проекта в смысле отсутствия лида во время собеседований). Меньше – подбор сотрудника затянется.
- Среднее время поиска Python-разработчика зависит от проекта, грейда и того, что может предложить ваша компания. В среднем 3 месяца от размещения заявки в HR до первого дня работы нового сотрудника это нормально.
- Ваш главный союзник в общегуманитарных вопросах собеседования - ваш HR.
- Не все разработчики – это тихие интроверты. Есть достаточное количество людей, которые умеют говорить, продавать себя и выучивать ответы для собеседований, не имея глубоких знаний. Не дайте себя обмануть, обязательно давайте задачки.
Гуманитарные вопросы
- Что кандидат делал на прошлых местах работы. Какую позицию занимал?
- Какой состав команды был на прошлых проектах (фронт, бэк, QA, админы, менеджеры)?
- Как был организован процесс планирования, постановки задач и ревью? Какие в этом были плюсы и минусы?
- Почему кандидат решил уйти (или уже ушел) с прошлого места работы?
- Что хотелось бы от нового проекта? В смысле задач и процессов?
Python
Проверка знаний, как развивается язык
- Расскажи, что появилось в последней версии Python? (Python 3.8 на момент создания статьи)
- В чем состоят основные различия между Python 2.7 и 3.0
- Какие синтаксические изменения произошли в языке после Python 2.7? (хочется услышать как минимум об asyncio и type hinting)
Основные типы и структуры данных в Python
- Назови основные типы данных в Python
- Расскажи, какие структуры данных есть в Python
- На какие два больших класса можно разделить типы/структуры данных? (mutable, immutable)
- Зачем вообще нужны immutable объекты? Почему нельзя везде использовать mutable?
- Какие строки в примере ниже выбросят исключение? Какие исключения?
d = {}
d['a'] = 1
d[(1,2)] = 2
d[[1,2]] = 3 # TypeError: unhashable type: 'list'
d[(1,2,[3,4])] = 4 # TypeError: unhashable type: 'list'
Порядок вычисления дефолтных аргументов функций
У нас есть функция:
def fun_default(val, lst: list=[]) -> list:
lst.append(val)
return lst
Какие значения будут иметь следующие списки после выполнения всего блока присваиваний:
l1 = fun_default(1)
l2 = fun_default(2, [])
l3 = fun_default(3)
print(l1) # [1, 3]
print(l2) # [2]
print(l3) # [1, 3]
Как поправить эту функцию, чтобы ответ был [1], [2], [3] соответственно?
def fun_default_fixed(val, lst: list=None) -> list:
if lst is None:
lst = []
lst.append(val)
return lst
Что такое декоратор?
- Что такое декоратор?
- Какие декораторы из коробки знаешь?
- Расскажи про протокол descriptor (сложный вопрос, можно раскручивать долго)
Декоратор, выводящий в stdout время выполнения функции
У нас есть функция, которая обращается в БД. Хочется, чтобы каждый вызов этой функции показывал в консоли время ее выполнения. Реализуй этот функционал с помощью декоратора. Допущение: декорируемая функция может иметь любое количество позиционных и непозиционных аргументов.
import time
def measure(func):
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
Применение декоратора
Как можно применить декоратор к функции fun, используя синтаксический сахар и без него?
# with syntactic sugar
@measure
def fun(l: list) -> None:
pass
# sugar free
fun = measure(fun)
type(fun) # function
Имя декорированной функции
Какое имя и docstring будут у функции после применения к ней декоратора?
fun.__name__ # 'wrapper'
fun.__doc__ # 'Wrapper function'
Как вернуть задекорированной функции оригинальное имя и doctring?
from functools import wraps
import time
def measure(func):
@wraps(func)
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
@measure
def fun(l: list) -> None:
"""My func"""
pass
fun.__name__ # 'fun'
fun.__doc__ # 'My func'
Как добиться того же эффекта без functools.wraps?
import time
def measure(func):
def wrapper(*args, **kwargs):
"""Wrapper function"""
before = time.time()
result = func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
wrapper.__doc__ = func.__doc__
wrapper.__name__ = func.__name__
return wrapper
Декоратор для генераторов
Какое время будет выводиться, если применить декоратор к генератору?
Допустим, мы применим написанный выше декоратор к такой функции:
from typing import Generator, Any
def fun_gen(l: list) -> Generator[Any, None, None]:
for i in l:
yield i
Почему в консоли время, выведенное декоратором, такое маленькое? Как замерить время итерации по всему генератору?
Этот вариант декоратора прокрутит генератор до конца и выведет общее время итерирования:
import time
from typing import Generator, Any
def measure_gen(func):
def wrapper(*args, **kwargs):
before = time.time()
result = yield from func(*args, **kwargs)
after = time.time()
print(f"Time elapsed: {after - before} seconds")
return result
return wrapper
@measure_gen
def fun_gen(l: list) -> Generator[Any, None, None]:
for i in l:
yield i
Декоратор с аргументами
Перепиши декоратор из задачи выше так, чтобы в него можно было передать аргумент, который будет устанавливать пороговое значение, начиная с которого будет выводиться время исполнения декорируемой функции:
def measure(limit):
# Don't forget to set limit when decorating a function!
def outer_wrapper(func):
def inner_wrapper(*args, **kwargs):
before = time.time()
result = func(*args, **kwargs)
after = time.time()
elapsed = after - before
if elapsed > limit:
print(f"Time elapsed: {after - before} seconds")
return result
return inner_wrapper
return outer_wrapper
Покажи, как использовать этот декоратор с синтаксическим сахаром и без него.
# syntactic sugar
@measure(3)
def fun(l: list) -> None:
pass
# sugar free
new_measure = measure(3)
fun = new_measure(fun)
fun([1,2,3])
Переменные класса
Что такое переменная класса?
Даны следующие классы:
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
Что выведут следующие строки?
print(Parent.x, Child1.x, Child2.x)
# 1 1 1
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
# 1 2 1
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
# 3 2 3
Слайсы в списках
Как исполнятся следующие строки?
l = [1, 2, 3, 4, 5]
l[1:2] # [2]
l[:-1] # [1, 2, 3, 4]
l[10:] # []
l[10] # IndexError
Что такое list/dict comprehensions?
Создай список квадрат четных чисел от [0, 10), используя list comprehension
[i*i for i in range(10) if i % 2 == 0]
То же самое, используя map и filter?
map(lambda x: x * x, filter(lambda x: x % 2 == 0, range(10)))
Generator expressions
Как превратить первый пример в generator (generator expression)?
(i*i for i in range(10) if i % 2 == 0)
Какие полезные функции из модуля functools ты знаешь?
Этот вопрос можно задавать после вопроса про декораторы и functools.wraps. В functools много всякого интересного. Хотелось бы услышать про reduce и особенно про partial.
Asyncio, multithreading, multiprocessing
- В чем разница между процессом и трэдом?
- Есть лист из 1к урлов, по каждому из них нужно сделать GET запрос. Как это сделать быстрее и дешевле? (IO-bound tasks -> asyncio, Tornado etc или multithreading)
- Есть 1к видеофайлов, которые надо отрендерить, или 1к программ, которые надо скомпилировать. Как это сделать быстрее? (CPU-bound tasks -> multiprocessing)
- Как устроен asyncio или аналогичные библиотеки для асинхронного программирования в Python? (огромный вопрос, который можно превратить в целое собеседование. Хочется как минимум понимания на уровне туториала Trio)
Экосистема языка
- Какие решения существуют для выполнения фоновых отложенных задач? (celery)
- Как сделать package из Python-кода? (wheels, eggs, в чем отличия?)
- Какие есть решения для документирования кода на Python? (sphinx-doc)
- Какие есть решения для документирования REST API (swagger)
- Назови ORM, с которыми ты работал (SQLAlchemy, Django ORM)
- Какие статические анализаторы кода, линтеры для Python ты знаешь? (mypy, flake8)
- Какие web-фреймворки тебе известны? (Flask, Django, aiohttp, sanic, etc.)
- Какие package management tools ты знаешь? (pip, pipenv, poetry, etc.)
Алгоритмы
Временная сложность
- Что такое временная сложность (time complexity)?
- Что такое большая O?
- Какая временная сложность вот такой операции:
# O(n^2)
for x in n:
for y in n:
print(x, y)
Какова временная сложность для следующих стейтментов?
x in/not in s # где type(s) is list/tuple # O(n)
x in/not in s # где type(s) is set # O(1)
list.append() # O(1)
list.insert() # O(n)
list[index] # O(1)
list.sort # O(n log n)
Можно еще поспрашивать временную сложность операций над другими структурами данных.
Проверка сбалансированности скобок в Lisp-программе
Я обожаю программировать на Racket – это диалект Lisp, который славится большим количеством скобочек. Напиши функцию на Python, которая будет получать на вход текст (строку) и возвращать True, если скобки в тексте сбалансированы и False в противном случае.
{kind=link}
Примеры сбалансированных скобочек:
"()"
"(())"
"(custom-set-variables '(inhibit-startup-screen t) '(package-selected-packages (quote
(sql-indent magit dockerfile-mode yaml-mode gitlab markdown-mode lorem-ipsum jedi
elpy anaconda-mode afternoon-theme))))"
"(hello [world {!}])"
Примеры несбалансированных скобочек:
"("
")("
"())"
"({))"
def balance(s):
"""
Return True if string's parentheses are balanced, False otherwise
>>> balance("")
True
>>> balance("(())")
True
>>> balance("))((")
False
>>> balance("()()(())(()())")
True
>>> balance("(]")
False
"""
opening = ("(", "[", "{")
closing = (")", "]", "}")
mapping = dict(zip(opening, closing))
stack = []
for ch in s:
if ch in opening:
stack.append(mapping[ch])
elif ch in closing:
if (not stack) or (ch != stack.pop()):
return False
return not stack
Если кандидату трудно придумать решение для скобочек разных типов, можно упростить задание до поверки, например, только круглых скобочек.
Базы данных
Зачем нужна RDBMS?
У нас стартап из CTO, CEO и одного разработчика. Админов нету. Мы пишем сервис аутентификации – регистрация пользотелей, проверка прав – на Python. Зачем нам нужна БД? Почему бы не использовать текстовый файл? Стандартная библиотека языка имеет все необходимое для работы с файлами. Записываем логин и хэш пароля при регистрации, читаем при запросе доступа. Это просто. Не требует админитрирования, избавляет от зависимостей. При сложностях, можно переформулировать вопрос так – какие существуют механизмы реляционной БД, достаточно сложные для их самостоятельно реализации, но необходимые для нашего случая?
От кандидата хочется услышать упоминания следующих механизмов:
- индекс
- связи таблиц
- транзакции
Про каждый механизм можно поспрашивать отдельно. Например, про индекс можно спросить:
- временная сложность для поиска по индексу
- в таблице candidates есть колонка is_interviewed с возможными значениями 0 и 1. какой прирост произодительности для поиска по этой колонке даст индекс для нее?
- что такое составные индексы? есть ли какие-то правила для запросов по колонкам, участвующим в составном индексе?
Запросы в MySQL/PostgreSQL
У нас есть сервис по типу iTunes, где можно арендовать/покупать видео. Вот схема таблиц реляционной базы, положим, в PostgreSQL
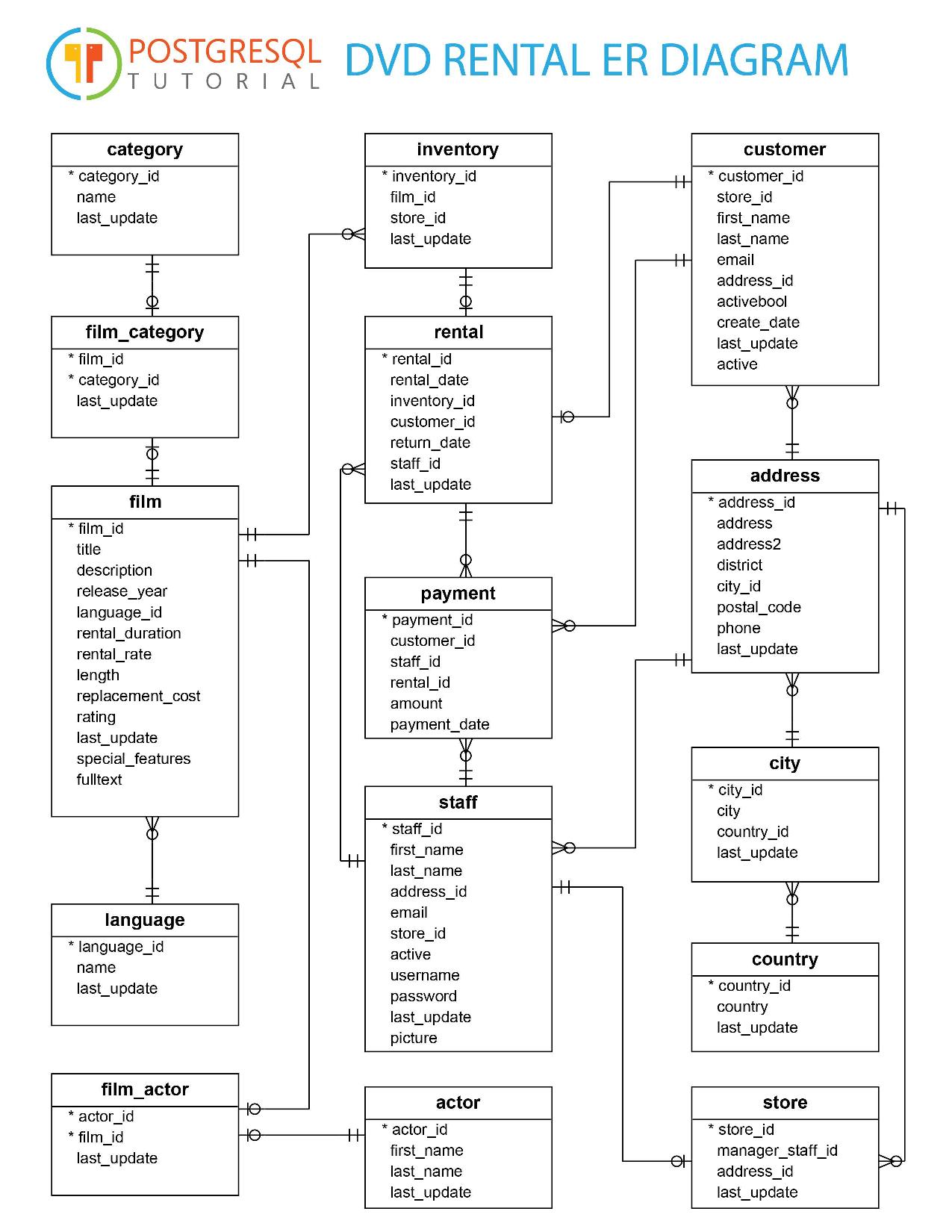
Напиши запрос, который выведет топ-20 фильмов, в которых играет актер John Doe. Запрос должен выводить:
- Название фильма
- Язык издания
- Год выпуска
Результаты нужно упорядочить по убыванию года выпуска.
(Если нужна подсказка) на основе таблиц: film, language, film_actor, actor
SELECT f.title, l.name, f.release_year
FROM film AS f
JOIN language AS l ON l.language_id = f.language_id
JOIN film_actor AS fa ON fa.film_id = f.film_id
JOIN actor AS a ON a.actor_id = fa.actor_id
WHERE a.first_name = 'John' AND a.last_name = 'Doe'
ORDER BY f.release_year DESC
LIMIT 20;
Напиши запрос, который выведет топ-10 клиентов, которые оставили в сервисе больше всего денег, но не менее 100 у.е. Запрос должен выводить:
- ID и полное имя клиента
- сумму всех заказов юзера
(Если нужна подсказка) на основе таблиц: payment, customer
SELECT c.customer_id, c.first_name, c.last_name, SUM(p.amount) AS money
FROM payment AS p
JOIN customer AS c ON c.customer_id = p.customer_id
GROUP BY c.customer_id
HAVING SUM(p.amount) >= 100
ORDER BY money DESC
LIMIT 10;
Общие представления о NoSQL
Что такое NoSQL БД? Какие типы NoSQL БД выделяют? Примеры
Хочется услышать хотя бы самые общие вещи: NoSQL БД — коллекция данных в одном из форматов (см. типы ниже). Данные денормализованы, JOIN реализуют обычно на уровне приложения.
Типы NoSQL БД:
- key-value store (реализация hash table: Redis, AeroSpike)
- document-store (аналогично key-value, но в качестве значения документ, например, JSON: MongoDB)
- wide column store (HBase, Cassandra)
- graph database (Neo4j)
Общие представления о Redis
Что такое Redis? Почему его так любят использовать для хранения кэшей? Чем, с точки зрения хранения данных, он принципиально отличается от, например, MySQL? Что произойдет с данными в Redis, если прозойдет рестарт сервера? Какие существуют механизмы для High Availability в Redis?
Ожидания от ответа: Redis – это in-memory key-value БД. У нее есть механизм снапшотов данных из памяти на диск. Для HA используют, например, Redis Sentinel
Тестирование
Общие представления о unit-тестировании
- Что это такое?
- Чем отличается от интеграционного, функционального тестирования?
- Какие библиотеки для Python использовал для этого? (unittest, pytest, в чем разница?)
- Когда нужно писать unit-тест? (в существующем проекте, в новом проекте, при починке бага, при реализации фичи)
Как протестировать функцию, которая изменяет запись в MySQL?
Есть функция, которая выполняет INSERT в тестовой базе данных MySQL, которой пользуются все разработчики команды. Нужно написать тест на эту функцию. Но не хочется вносить изменения в общую базу. Как можно решить эту проблему?
- mock
- transaction rollback
DevOps/Администрирование
Проблема с нечитаемым ответом google.com
Я захожу на https://www.google.com в браузере, открываю исходный код и вижу вполне читаемый текст.
Но если я делаю такой запрос через curl то вижу нечто нечитаемое, похожее на бинарный файл:
> GET / HTTP/2
> Host: www.google.com
> User-Agent: curl/7.58.0
> Accept: */*
> Accept-Encoding: gzip, deflate
%�j��~d+.K�W��me`�,x�x�m�G�67��`$#������~{d���]�.'����
����Q���Mʥu���<�O),�&�����,���E�.���_�
&�I\��p��#]�,�����K+����p�vk
j���k"�fe�=�`�J4�I/��m6{�E���;3+�v�BT1T��(W��J��m�yO��
�j��
Почему так происходит?
Для интервьюера:
curl -v "https://www.google.com" --header "Accept-Encoding: gzip, deflate" --output -
Топ IP адресов из лога NGINX
Наш сервис парсят боты. Это создает большую нагрузку, мешающую нормальным пользователям. Мы решаем забанить ботов по IP-адресам. Для этого мы хотим составить топ IP-адресов, с которых приходили запросы. Мы просим админов сделать выгрузку логов за 1 час.
С помощью стандартных GNU utils создай файл с топом IP-адресов в порядке убывания частоты запросов. Предположим, что IP-адрес находится в 9-й колонке лога, колонки отделяются через t
awk '{print $9}' nginx.log | sort | uniq -c | awk '{print $1","$2}' | sort -r -t, -nk1 > bots.csv
Docker
- Что такое докер контейнер?
- В чем отличие от virtualbox и других виртуальных машин?
- Зачем использовать докер, если можно просто скопировать файлы на машину?
- Почему нельзя просто использовать virtualenv?
Архитектура
Parental advisory: highly opinionated content (35+)
Проектирование сервиса копипасты pastebin
Бизнес-описание
- Пользователь сабмитит текст
- Текст сохраняется, ему присваивается уникальный URL
- По переходу по сгенерированному URL мы видим текст
- Текст хранится какой-то срок (в минутах)
- Сервис удаляет просроченные тексты
- Сервис высоконагруженый
- Нужна статистика для посещения различных урлов по месяцам
Ограничения и допущения
- Пасты только текстовые
- Аналитика может быть не реалтаймовой
- 10 миллионов записей в месяц (3.85 RPS)
- 100 миллионов чтений в месяц (38.5 RPS)
- Железо планируем на 3 года вперед
Ответить соискателю, если спросит
- Средний размер пасты 1Kb
- Короткая ссылка длиной 7 байт в БД
- TTL ссылки в минутах 4 байта в БД
- Время создания ссылки 5 байт
- Путь хранения файла пасты - 255 байт
- Итого: 1.27 Кбайт на 1 пасту
1.27 Гб пасты в месяц За 3 года: - 36 * 12.7 = 457 Гб пасты - 36 * 10 = 360 млн урлов
Крупноблочная схема архитектуры
Client
|
V
Load Balancer
|
V
Web Server (Reverse Proxy, i.e. Nginx)
| |
V V
Write Read Analytics (MapReduce)
API API--------------------------- | |
| | | | | |
| V | | | |
| Cache | | | V
------------------------------ | | SQL for Analytics
V | | | |
SQL----------- | V V V
|_Master | | Object (File) Store
|_Slave V |
SQL V
^ Read-only Replica
|
|
Periodic Task
(remove expired)
Write API
- Генерит URL, проверяет уникальность в SQL
- Если уникальное, делает INSERT в таблицу, иначе идет в п. 1
shortlink char(7) NOT NULL
expiration_in_minutes int NOT NULL
created_at datetime NOT NULL
paste_path varchar(255) NOT NULL
PRIMARY KEY(shortlink)
CREATE INDEX shortlink_idx ON pastes (shortlink) USING BTREE;;
CREATE INDEX created_at_idx ON pastes (created_at) USING BTREE;;
Создание уникального урла
- Берем рандомную строку (или IP address юзера + timestamp) и вычисляем MD5
- Кодируем Base 62 (как Base 64 но без escape-символов)
def base_encode(num, base=62):
digits = []
while num > 0
remainder = modulo(num, base)
digits.push(remainder)
num = divide(num, base)
digits = digits.reverse
От строки в Base 62 можем взять 7 символов это даст 62**7 возможных значений (это намного больше чем 360 миллионов урлов, которые мы планируем на 3 года)
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
Запрос к Write API
$ curl -X POST https://pastebin.com/api/v1.0/paste \
--data '{ "expiration_in_minutes": "60", "paste_contents": "My paste" }'
Ответ Write API
{
"shortlink": "xJlsmeT"
}
Запрос к Read API
$ curl https://pastebin.com/api/v1.0/paste?shortlink=xJlsmeT
Ответ Read API
{
"paste": "My paste"
"created_at": "YYYY-MM-DD HH:MM:SS"
"expiration_in_minutes": "60"
}
Аналитика
Поскольку не нужен реалтайм, будем брать логи с реверс прокси и скартимливать их в MapReduce
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Emit key value pairs of the form:
(2016-01, url0), 1
(2016-01, url0), 1
(2016-01, url1), 1
"""
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key.
(2016-01, url0), 2
(2016-01, url1), 1
"""
yield key, sum(values)
Полезные ссылки
- Toptal Python Interview Questions
- Python Interview Questions (junior, middle, senior)
- System design interview
- The Python Language Reference
- PostgreSQL Tutorial
Errata
2020-04-18. В функции проверки сбалансированности скобок исправлена ошибка в маппинге. Для хранения ключей и значений использовались структуры типа set (не гарантируют сохранения порядка вставки элементов). Исправлено на tuple. Нашел ошибку Егор Моренко.